blog
今年読んだ応用検索論文の紹介
この記事は情報検索・検索技術 Advent Calendar 2024 の 22 日目の記事として執筆されました.
概要
本記事では,今年読んだ応用検索論文についていくつか紹介をします.応用検索論文というのは本記事の著者が今適当に考えたワードで,主に以下の特徴を持つ傾向にあります.
Learning to Rank for Maps at Airbnb (KDD 2024) を読んだ
- タイトル: Learning to Rank for Maps at Airbnb
- URL: https://arxiv.org/abs/2407.00091
- KDD 2024, Applied Data Science Track
概要
- Airbnb には検索結果の表示方法が以下の図のように 2 つのある: (1) リスト表示,(2) 地図表示
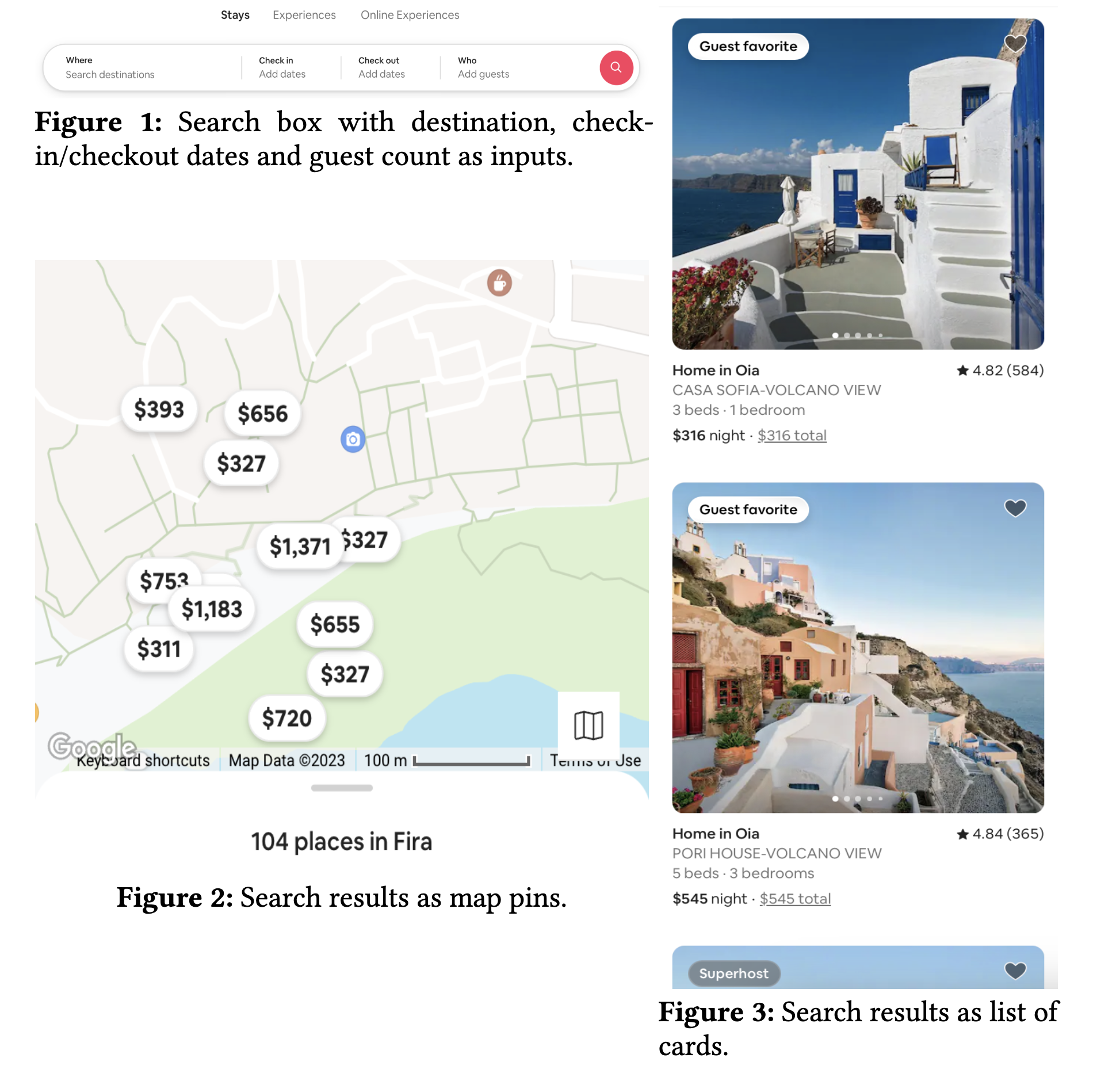
Airbnb における検索ボックス,リスト表示,地図表示(図は論文より引用) - リスト表示における単純な仮定「ユーザはランキングの上から順にアイテムを見る」が,地図表示では成立しないことから出発し,地図表示特有の様々な改善を実施したよ,という論文
背景: Map ≠ List
- 検索結果の評価においては,リスト表示を前提とした nDCG が一般的に使われる
- リスト表示と地図表示が全然異なるという例
- 予測確率上位 N 個の宿をランダムな順序にする A/B テストは,リスト表示では予約数 8% 減,nDCG 5% 減と大きな悪化
- 地図表示で同様の実験をすると,(当たり前だが)指標に変化はなかった
施策 1: 表示数の調整(Section 3, 4, 5)
- 前提: (クエリ Q による検索で予約が発生する確率) = Σ_i (順位 i の宿が見られる確率) * (順位 i の宿の予約確率)
- nDCG ではユーザが 1 位から順にアイテムを見ていくため,(順位 i の宿が見られる確率) は i が小さいほど高いという仮定があるが,この仮定は地図表示では成立しない
- (順位 i の宿が見られる確率) のことを,これ以降では (順位 i の宿の注意) と呼ぶ
- リスト表示においては,i < j のとき,(順位 i の注意) > (順位 j の注意) が成立
- nDCG ではユーザが 1 位から順にアイテムを見ていくため,(順位 i の宿が見られる確率) は i が小さいほど高いという仮定があるが,この仮定は地図表示では成立しない
- 仮説: 地図表示においては,(順位 i の注意) = (順位 j の注意) = 1/N となるのでは?(N は表示する宿の数)
- このとき,(クエリ Q による検索で予約が発生する確率) = 1/N Σ_i (順位 i の宿の予約確率) = (表示する宿の平均予約確率)
- つまり,地図で表示するアイテムを予約確率が高いものに絞ることで,予約数向上が見込める!
- 提案手法: Bookability Filter
- N 個の候補のうち,logit(宿の予約確率の最大値) - logit(宿 i の予約確率) > α の宿のみ選択し,地図に表示(Algo.1)
- α はハイパーパラメータ,実験により 1.0 に設定
- N 個の候補のうち,logit(宿の予約確率の最大値) - logit(宿 i の予約確率) > α の宿のみ選択し,地図に表示(Algo.1)

Bookability Filter - 実験: 地図を単体で表示するモバイルのみに絞って A/B テストを実施
- control が 18 個固定,treatment が提案手法
- 結果: 提案手法が p値 0.00001 未満,予約数 1.9% 増で過去数年で最大の改善策の 1 つに
- さらなる改善: 宿の予約確率の最大値だと外れ値の影響を受けるので,top-n(n はヒット件数に依存する定数)の中央値を採用 → 各種指標を悪化させずに表示件数を増やすことに成功
- これは本当にユーザの検索体験を向上させたのか?
- 疑問: 表示される宿の数が減ったことで,ユーザは予約可能な残りの宿が少ないと考えて急ぎで予約し,その結果,予約数が増えたのでは?(緊急性仮説)
- 実験結果: 18 個固定 vs 14 個固定で A/B テストを実施した結果,緊急性の仮説は否定された
施策 2: 異なる注意と 2 種類のピン(Section 6)
- 前提: モバイルとは違って,Web はリストと地図が同時に表示される(Fig.8)
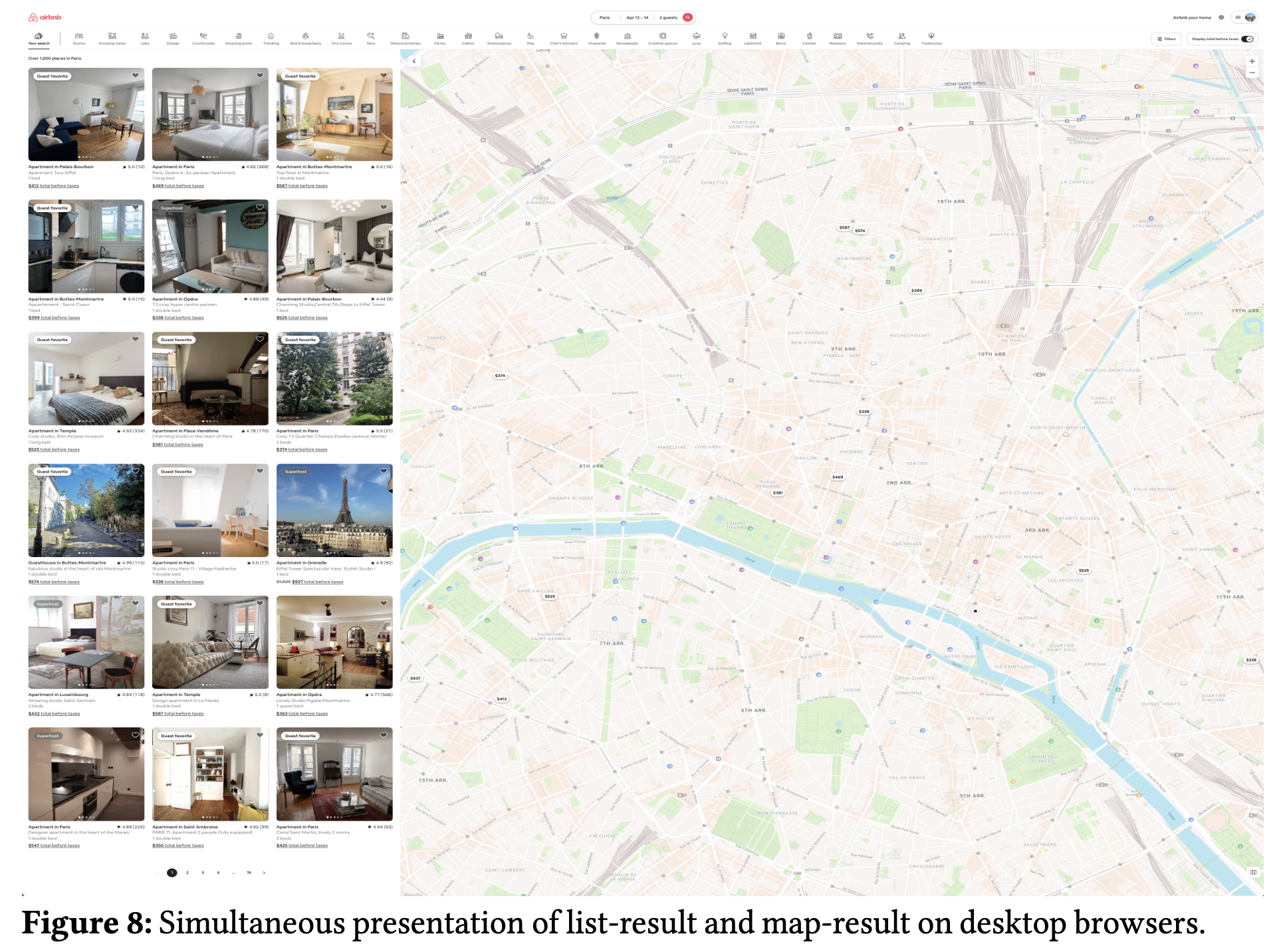
- 加えて,地図においては値段が表示される通常のピンと,値段が表示されない小さいピン(ミニピン)が存在(Fig.9)
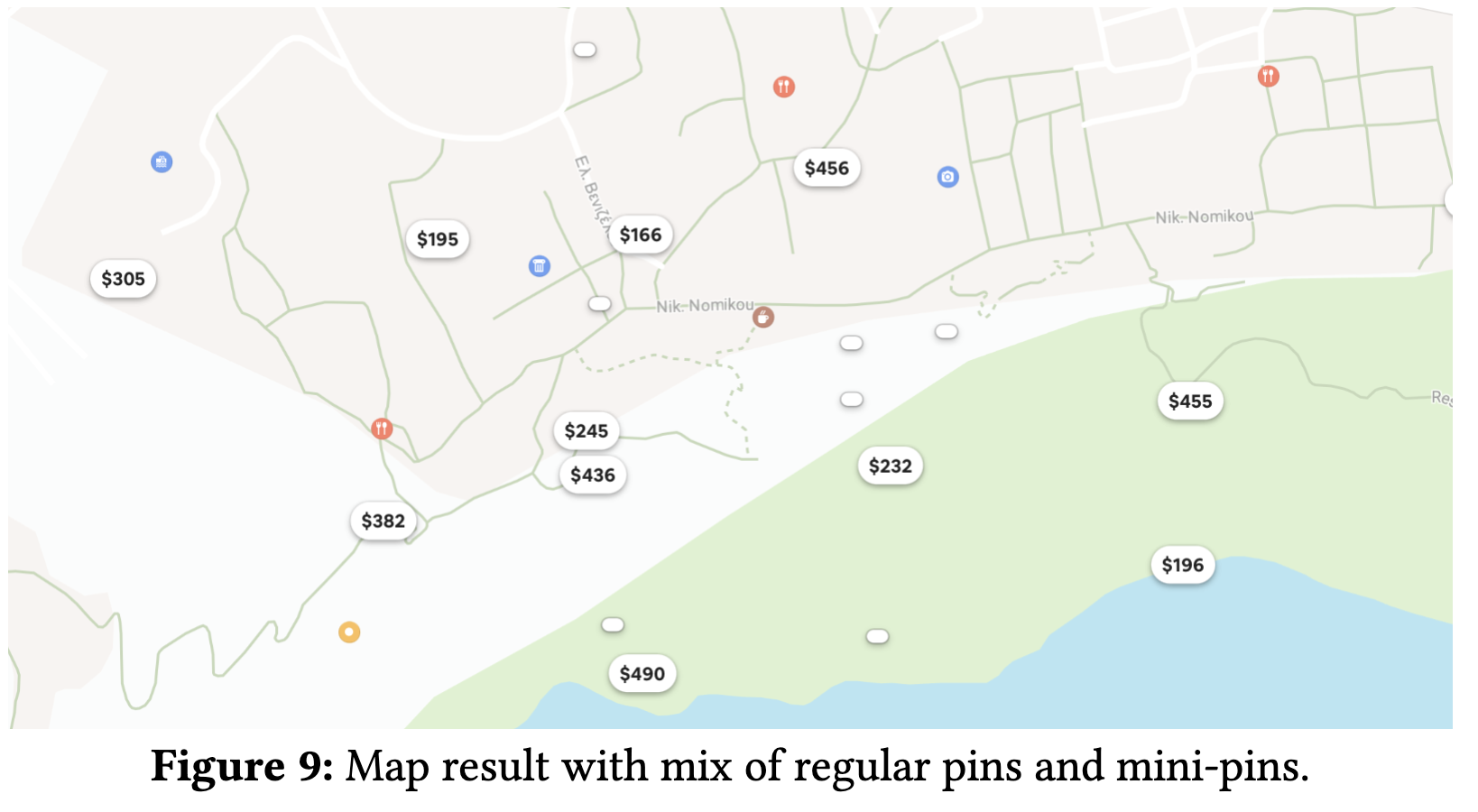
- 仮説: 通常ピンとミニピンでは CTR に 8 倍の差があるので,注意にも差があるはず
- なので,どの宿を通常ピン or ミニピンで表示するかを変えることで,検索からの予約数も変わるのでは?
- 提案手法: Bookability Filter で選ばれた宿を通常ピン,残りをミニピンで表示
- 結果: A/B テストで予約数 0.7% 増
施策 3: 地図上の注意と表示の最適化(Section 7)
- 前提: 地図表示においては,表示の中心の宿ほど CTR が高い(Fig.10)
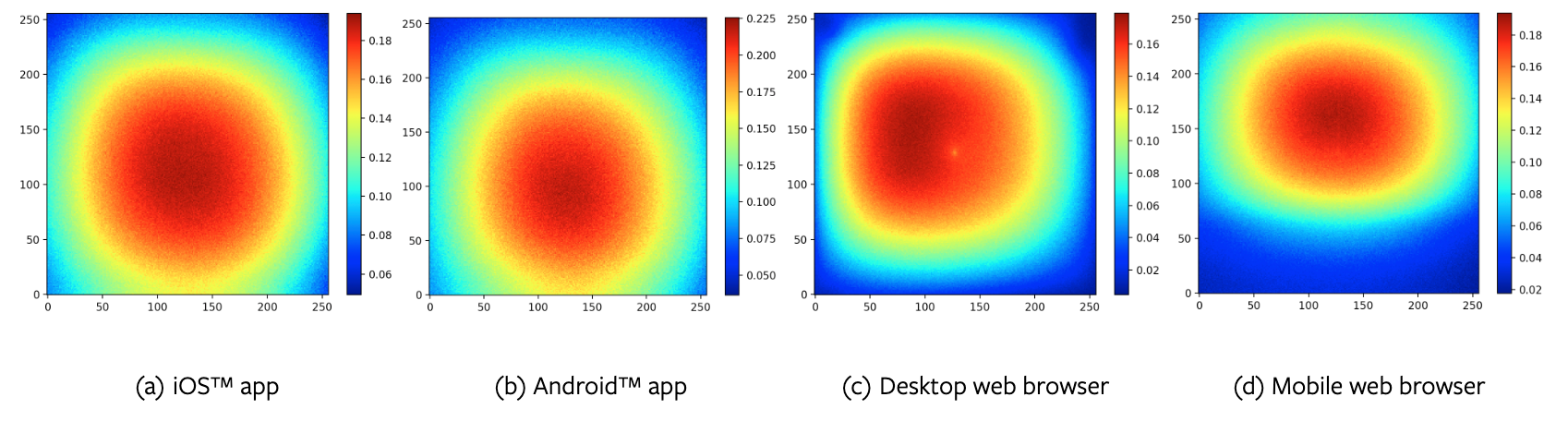
- 仮説: 地図表示においては,中心に位置する宿ほど注意が高いはず
- つまり,中心の位置を変えて,中心に表示する宿を変えれば,検索からの予約数も変わるのでは?
- 提案手法: 中心からの相対位置を考慮した注意(式 6)を元に,中心を位置を最適化する手法を提案
- 手法: 地図をセルに等分割し,各セルを中心にしたときの (あるクエリ Q が予約される確率) が最大になる位置を中心とする(Algo.2)
- A/B テスト結果: 検索からの地図表示において,提案手法が p値 0.006,予約数 0.39% 増加
- 分析: ユーザが能動的に地図を移動させる割合も 1.5% 減っており,良い中心が設定できていることが分かった
まとめ
- これまでは,地図は特別扱いされることなく,あまり研究されてこなかった
- 本研究では,通常の研究が注力する宿の予約確率の予測ではなく,宿の注意に着目しモデル化することで,予約数などの各種指標を向上することができた.
- 今後の課題: さらなる注意のモデル化,バイアスの問題,ピンの種類,表示の最適化,public dataset の作成
所感
- 論文というよりテックブログ的な印象だが,内容は面白いし,地図表示には研究の余地があるよねという点を示したのはコミュニティ的には大事という話と理解した
- Point-of-interest の推薦とかと関連ありそうだけど,関連研究として提示されてなさそうだった.なんでだろか.
- Airbnb 検索は KDD18, 19, 20, 23, 24 とずっと KDD で発表しつづけていてすごい
AtCoder で scipy を使って問題を解く
AtCoder で scipy を使って解いた問題をメモ代わりに残しておきます.一部 yukicoder や Library-Checker も含まれています(タイトル詐欺).
AtCoder に入っている numpy / scipy のバージョンはコードテストに以下を入力して実行することで確認できます.
情報検索:検索エンジンの実装と評価 第 8 章 確率的情報検索
この記事は 「情報検索:検索エンジンの実装と評価」(Buttcher本) Advent Calendar 2020 の 25 日目の記事です.
この記事では第 8 章を最初から解説する…予定だったのですが,8.1 から 8.5 までの話,つまり確率的ランキング原理から BM25 の導出までについては,既に素晴らしい日本語解説が存在するため,この部分に関してはそちらを御覧ください12.また,導出などはどうでもいい,とにかく BM25 の式の意味を知りたい,という人は解説動画34を見るとよいと思います.TF-IDF から BM25 までを非常に平易に説明してくれています.
LightGBM でかんたん Learning to Rank
概要
LightGBM には LambdaRank が実装されており,簡単にランキング学習ができるようになっている. しかし残念なことに,日本語で試してみた例は非常に少ない. 特に,実際にデータ用意して学習し,評価するところまでやって公開している例がほぼ見当たらない.
Manhattan Minimum Spanning Tree
問題
解法
- NOTE: ここで述べる解法は基本的に以下の topcoder の記事を参考に分割統治部分を座標圧縮+セグメント木で置き換えたものである.
ナイーブに考えると,全点対でマンハッタン距離を計算して Kruskal 法などの最小全域木を求めるアルゴリズムを適用すればよいと思えるが,この解法では入力の頂点数 $N$ に対して,枝数が $O(N^2)$ になってしまう.
第4回 統計・機械学習若手シンポジウム「Academic Writing for Top Conferences」聴講録
概要
2019/11/15(金)・16(土) に名古屋(名工大)で開催された、第 4 回統計・機械学習若手シンポジウムに参加してきました。
その中でも「Academic Writing for Top Conferences」というセッションは個人的に有用そうだと思ったので共有します。 後半の「第2部:パネルディスカッション・質疑応答」については、Q&A 集が公開されています (URL)。
機械学習・データマイニング・人工知能分野周りの日本所属の国際会議論文を集めてみる
概要
学生が研究室を選んだり、企業が共同研究先を選ぶ際に、その研究室がきちんと論文を通している研究室かどうかというのは一つに基準になるかと思います。計算機科学分野、特に機械学習・データマイニング・人工知能分野周りの分野では、企業の研究所が強く速報性が求められる影響などにより国際会議論文の影響力が強い傾向があります。そこで本記事では、これらの分野の国際会議に日本所属で論文を通している人を収集することを考えます。
連続する部分列の和の総和
問題
- 長さ $N$ の数列 $A = [a_1, a_2, ..., a_N]$ が与えられる
- この数列の任意の連続する部分列の和の総和を $10^9+7$ で割った余りを求めよ
例
$A = [1, 2, 3]$ のとき、和は $1+2+3+(1+2)+(2+3)+(1+2+3)=20$
制約
- $1 \le N \le 10^6$
- $-10^9 \le a_i \le 10^9 (i = 1, ..., N)$
解法
- $A$ の累積和を取った数列を $S$ とする
- つまり、$S_i := \sum_{j=1}^{i}a_j$
- ただし、$S_0 = 0$ とする
- このとき、求める総和は、$\sum_{(i,j):0 \le i < j \le N}(S_j - S_i)$ と書ける
- $(i,j):0 \le i < j \le N$ は $0 \le i < j \le N$ を満たす組 $(i,j)$ を意味する
- これは和と差しか出てこないため、正の項 $S_j$ と負の項 $-S_i$ がそれぞれ何回この式の中で現れるかを考えればよい
- 正の項 $S_j(j=0,1,...,N)$ が何回現れるかを考えると、$S_0$ は0回、$S_1$ は 1 回 ($i=0$ のとき)、$S_2$ は 2 回 ($i=0,1$ のとき)、と考えていくと、正の項 $S_j$ は $j$ 回現れる
- 負の項 $S_i(i=0,...,N-1)$ が何回現れるかを考えると、$S_0$ は $N$ 回 ($j=1,2,...,N$ のとき)、$S_1$ は $N-1$ 回 ($j=2,i...,N$ のとき) と考えていくと、$S_i$ は $(N-i)$ 回現れる
- よって、$\sum_{(i,j):0 \le i < j \le N}(S_j - S_i)=\sum_{i=0}^{N}(i \times S_i - (N-i)\times S_i)=\sum_{i=0}^{N}(2i-N)S_i$ となる
- 以上より、$O(N)$ で問題を解くことができた
コード
def sum_subarrays(A, mod=10**9+7): N = len(A) S = [0] for a in A: S.append(S[-1] + a) S[-1] %= mod return sum((2 * i - N) * s % mod for i, s in enumerate(S)) % mod- 負の剰余が出てくるが、Python (2/3系ともに) では負の数 $x(x>0)$ の正の数 $m(m>0)$ についての剰余 $x\%m$は$(x+m)\%m$ と一致するため、問題ない
- C++ ではこのコードは問題が出る
- 負の数の剰余の計算で負の数が出る場合の計算は、言語仕様によって異なるため、注意したほうがよい
類題
- 連続でなくてよい場合は、総和において各数は $2^{N-1}$ 回出現する
- よって答えは $2^{N-1}\times\sum_{i=1}^{N}a_i$
- 和ではなく積の場合も同様に求められる
- $P_0 := 1, P_i := \prod_{j=1}^{i}a_j (i=1,\ldots,N)$ とすると、$\prod_{(i,j):0 \le i < j \le N} \frac{P_j}{P_i}=\prod_{i=0}^{N} \frac{P_i^i}{P_i^{N-i}}=\prod_{i=0}^{N}P_i^{2i-N}$
- 和ではなく bitwise xor の場合も同様で、ビットごとに偶数回か奇数回かを考えればよい
- 連続する部分列の長さが $K$ 以下という制約がある場合
- これは正の項 $S_i$、負の項 $-S_i$ が出現する回数が $K$ 回以下という条件だと考えればよいので、答えは $\sum_{i=0}^{N}(\min(i, K) \times S_i - \min(N-i, K)\times S_i)$
- 連続する部分列の長さが $K$ 以上という制約がある場合
- $\sum_{i=0}^{N}(\max(i-K+1, 0) \times S_i - \max(N-i-K+1, 0)\times S_i)$
参考
pelican(python3)で日本語のカテゴリやタグごとのページのurlを変更する方法
- 動作環境
- Python 3.6.1
- pelican 3.7.1
状況
pelicanでタグ毎にページを表示するurlは
tag/(タグ名).htmlであるが、日本語のタグを付けたときにはurlの(タグ名)の部分がよく分からない文字列に自動変換される。 正確にはアルファベットと数字以外の文字列を使った場合であり、これはカテゴリでも同様である。- 動作環境
(論文メモ) Improving Hypernymy Detection with an Integrated Path-based and Distributional Method (ACL2016)
書誌情報
- title
- Improving Hypernymy Detection with an Integrated Path-based and Distributional Method
- author
- VeredShwartz, Yoav Goldberg, Ido Dagan
- Bar-Ilan University, Israel
- VeredShwartz, Yoav Goldberg, Ido Dagan
- venue
- ACL 2016
- url
- その他
- ACL 2016 Outstanding Paper Award
解くべき問題は何か?
- 単語の組(x,y)に対して、yがxの上位語であるかどうかを推定
- 例: x = トム・クルーズ, y = 俳優 -> yはxの上位語である
- 質問応答などで有用な応用がある
既存法との違いは何か?
- 構文解析木ベースの手法を、構文木をRNN-LSTMでencodeする手法を提案し、state of the artに近い評価値を達成
- 1の手法と分散表現ベースの手法を組み合わせる手法を提案して、state of the art を達成
この手法は以下の図で大体説明できる。
- title
確率分布早見表
離散分布
確率分布 確率密度関数 定義域 パラメータ 平均 分散 ベルヌーイ分布 $p^x (1-p)^{1-x}$ $x\in \{0,1\}$ $p$ $p$ $p(1-p)$ 二項分布 ${}_nC_xp^x(1-p)^{n-x}$ $x\in \{0,\cdots,n\}$ $n,p$ $np$ $np(1-p)$ ポアソン分布 $\frac{\lambda^xe^{-\lambda}}{x!}$ $x\in \{0,1,\cdots\}$ $\lambda$ $\lambda$ $\lambda$ 幾何分布 $p(1-p)^{x-1}$ $x\in \{1,2,\cdots\}$ $p$ $\frac{1}{p}$ $\frac{1-p}{p^2}$ (離散)一様分布 $\frac{1}{N}$ $x\in \{1,\cdots,N\}$ $N$ $\frac{N+1}{2}$ $\frac{N^2-1}{12}$ 連続分布
確率分布 確率密度関数 定義域 パラメータ 平均 分散 正規分布 $\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)$ $(-\infty,\infty)$ $\mu,\sigma$ $\mu$ $\sigma^2$ 指数分布 $\lambda e^{-\lambda x}$ $[0,\infty)$ $\lambda$ $\frac{1}{\lambda}$ $\frac{1}{\lambda^2}$ (連続)一様分布 $\frac{1}{b-a}$ $[a,b]$ $a,b$ $\frac{a+b}{2}$ $\frac{(a-b)^2}{12}$ 仮説検定早見表
正規母集団に対する仮説検定
- 『統計学入門』第12章より
早見表
何の検定 検定統計量 自由度 分布 母平均(母分散既知) $\frac{\overline{X}-\mu}{\sqrt{\sigma^2/n}}$ 標準正規分布 $N(0,1)$ 母平均(母分散未知) $\frac{\overline{X}-\mu}{\sqrt{s^2/n}}$ $n-1$ t分布 母分散 $\frac{(n-1)s^2}{\sigma_{0}^2}$ $n-1$ $\chi^2$ 分布 2分布の平均(分散が等しい) $\frac{\overline{X}-\overline{Y}}{\frac{(m-1)s_1^2+(n-1)s_2^2}{m+n-2}\sqrt{\frac{1}{m}+\frac{1}{n}}}$ $m+n-2$ t分布 2分布の平均(分散が等しくない) $\frac{\overline{X}-\overline{Y}}{\sqrt{s_1^2/m+s_2^2/n}}$ $\frac{(s_1^2/m+s_2^2/n)^2}{\frac{(s_1^2/m)^2}{m-1}+\frac{(s_2^2/n)^2}{n-1}}$に最も近い整数 t分布 2分布の分散 $\frac{s_1^2}{s_2^2}$ $(m-1, n-1)$ F分布 表の度数分布 $\sum_{i=1}^k\frac{(f_i-np_i)^2}{np_i}$ $k-1$ $\chi^2$ 分布 分割表の属性の独立 $\sum_{i=1}^r\sum_{j=1}^c\frac{(nf_{ij}-f_{i\cdot}f_{\cdot j})^2}{nf_{i\cdot}f_{\cdot j}}$ $(r-1)(c-1)$ $\chi^2$ 分布 母平均に関する検定
- 母分散が既知のとき
- 検定統計量 $Z$ は $\overline{X}$ の標準化変数 である
- つまり $Z=\frac{\overline{X}-\mu}{\sqrt{\sigma^2/n}}$ である
- 帰無仮説が正しければ、これは 標準正規分布N(0, 1) に従う
- 母分散が未知のとき
- 検定統計量 $Z$ は $\overline{X}$ の標準化変数の母分散 $\sigma^2$ を不偏分散 $s^2$ に置き換えたもの である
- つまり $Z=\frac{\overline{X}-\mu}{\sqrt{s^2/n}}$ である
- 帰無仮説が正しければ、これは 自由度 $n-1$ のt分布 $t(n-1)$ に従う
- これをスチューデントのt検定と呼ぶ
母分散に関する検定
- 検定統計量は $\chi^2=\frac{(n-1)s^2}{\sigma_{0}^2}$
- これは帰無仮説のもとで 自由度 $n-1$ の $\chi^2$ 分布 に従う
- これを $\chi^2$ 検定という
母平均の差の検定
2つの分布の結果に差があるかどうかを検定する
Github Pages はじめました
Github Pages はじめました
pelicanでサイトを作ったので、競プロライブラリの公開とか、なにかメモ的なものとして使いたい
- highlightのテスト
import math print(math.sqrt(4)) print("Hello World!")- mathjaxのテスト
$\alpha$が$\beta$を$\kappa$らったら$\epsilon$した。なぜだろう。 (参考: アルファがベータをカッパらったらイプシロンした。なぜだろう。)