情報検索:検索エンジンの実装と評価 第 8 章 確率的情報検索
Table of contents
この記事は 「情報検索:検索エンジンの実装と評価」(Buttcher本) Advent Calendar 2020 の 25 日目の記事です.
この記事では第 8 章を最初から解説する…予定だったのですが,8.1 から 8.5 までの話,つまり確率的ランキング原理から BM25 の導出までについては,既に素晴らしい日本語解説が存在するため,この部分に関してはそちらを御覧ください12.また,導出などはどうでもいい,とにかく BM25 の式の意味を知りたい,という人は解説動画34を見るとよいと思います.TF-IDF から BM25 までを非常に平易に説明してくれています.
この記事では,8.6 と 8.7 について解説をしていきます.
8.6 Relevance Feedback(適合性フィードバック)
これまで BM25 について説明してきましたが,その途中にもいくつかのスコア関数が出てきました.バイナリ独立モデルもその一つであり,スコア関数は以下の式で表されます.
$$ \sum_{t \in q \cap d} w_t = \sum_{t \in q \cap d} \log \frac{p_t(1-\bar{p_t})}{\bar{p_t}(1-p_t)} $$ただし,各記号は以下の通りです.
- $q,d$: それぞれクエリと文書に含まれる語の集合
- $p_t=p(D_t=1|r), \bar{p_t}=p(D_t=1|\bar{r})$: 文書において語 $t$ が出現する確率
- $D_t$: 語 $t$ が出現するかどうかを表す確率変数
- $r, \bar{r}$: それぞれ適合,不適合を表す
なぜこのスコア関数を直接ランキングに用いずに,BM25 を導出しようとしていたのでしょうか?この理由として考えられるのは,$p_t, \bar{p_t}$ などを推定するためには,それぞれのクエリに対して適合文書/不適合文書が必要であるためだと推測できます.つまり,任意のクエリに対してアノテーション(適合性判定)を行う必要があり,現実的ではありません.しかしこれらを正しく推定することができれば,よりよい検索結果を返すことが可能になるかもしれません.
また,確率的ランキング原理からバイナリ独立モデルを導出する過程では,仮定 Q の存在がありました.この仮定により,クエリに出現しない単語は適合性に影響しないものとして無視されてしまっていました.しかしクエリに出現しなくても適合性に影響を与える語が存在することは容易に想像できます.例えばクエリに含まれる語の同義語は適合性に影響を与えそうです.また別の例としては,ユーザの持つ情報要求をユーザ自身が適切にキーワードクエリとして落とし込めていない場合なども,ユーザの情報要求とは合致するがクエリには存在しないが語が,適合かどうかに影響を与えそうです.
適合性フィードバックは上記で述べた 2 つの問題(推定には適合性判定が必要であるという問題,クエリに存在しないが適合性に影響を与える語が存在するという問題)に対処するための手法です.適合性フィードバックは以下の流れで処理を行います,
- ユーザは検索エンジンにクエリを入力する.
- 検索エンジンはなんらかのスコア関数でランキングを提示する.
- ユーザは検索結果に対して,適合性判定を行う.つまりランキング上位の文書に対して,適合/不適合を判定する.
- 検索エンジンは与えらた適合性判定結果をもとに,適合文書からいくつかの単語をクエリに追加して再度検索を行う.
もとのクエリに対して,いくつかの単語を追加することで検索結果を改善することはクエリ拡張と呼ばれています.
しかしながら,適合性フィードバックはユーザが検索結果に対して適合性判定を行う必要があり,ユーザの負担となるという問題があります.そこで,最初の検索結果において上位にランク付けされる文書はある程度適合しているはずだという仮定をおき,上位の文書は必ず適合文書であるとみなして適合性フィードバックを行う手法が研究されています.この手法は疑似適合性フィードバックと呼ばれています.疑似適合性フィードバックは,教科書の例や実験結果のように性能を向上させる可能性もある一方で,上位の文書には適合文書が多く含まれているという仮定が成立しない場合には性能が落ちてしまう可能性も十分にありうるため注意が必要です.
8.7 Field Weights: BM25F(フィールドの重みを考慮した検索: BM25F)
情報検索において,検索対象のアイテム(文書)が複数のフィールドを持つことは多いです.例えば Web ページはタイトルと中身の文書(本文)などのフィールドを持ちます.また,Web 検索においては,他の文書からのアンカーテキストが検索において有効であると言われており.これも 1 つのフィールドとみなすことができます.このような検索は Multi-field Retrieval(複数フィールド検索,マルチフィールド検索)と呼ばれており,以下のような検索が例としてあげられます.
- Web 検索: タイトル,中身の文書(本文),URL,アンカーテキスト,クリックされたクエリ 5
- 商品検索: タイトル,説明,カテゴリ,メタデータ,ブランド,大きさなどの数値,過去の検索クエリ 6
- レシピ検索: タイトル,説明文,材料,レシピが公開された国 7
- 表検索
- Web 上の表の場合: ページタイトル,セクションタイトル,表のキャプション,表の列名,表の中身 8
- 学術論文: タイトル,概要, 著者,セクション,図表,Venue,年,キーワード,引用先論文,被引用論文
ここではフィールドはすべてテキストであり,またクエリはキーワードクエリであると仮定して話を進めていきます(このような検索タスクはアドホック(文書)検索と呼ばれており,情報検索において最も基本的な検索タスクです).
複数フィールド検索において特徴的なこととして,検索対象のアイテムが持つフィールドはそれぞれ性質が異なるという点があげられます.
- 文章の長さ: タイトルは短い一方で中身は長いことが多いなど,フィールドに含まれる文章の長さが異なる可能性がある
- 単語の出現頻度: タイトルには抽象的な単語が用いられる一方で,本文では具体的な単語が用いられるなど,同じ単語でもフィールドごとに出現頻度が異なる可能性がある
ここまで考えてきた BM25 は文章の長さや単語の出現頻度の情報をスコア計算に使う手法であるため,フィールドごとに大きくスコアが変化するはずであることが推測されます.では BM25 においてフィールドごとに異なる情報をどのように組み合わせればよいでしょうか?
BM25F910 はフィールドごとの(擬似的な)単語頻度の重み付き和を用いてフィールドごとの情報を統合する検索手法です.BM25 におけるクエリ $t$ のスコアは以下の式で表されます.
$$ \frac{f_{t,d} (k_1 + 1)}{k_1 \left((1-b)+b\frac{l_d}{l_{\mathrm{avg}}}\right) + f_{t,d}} w_t = \frac{f_{t,d}' (k_1 + 1)}{k_1 + f_{t,d}'} w_t $$ただし,$f_{t,d}'=\frac{f_{t,d}}{(1-b)+b\frac{l_d}{l_{\mathrm{avg}}}}$ であり,$w_t$ は任意のロバートソン/スパルク・ジョーンズ重み付け(実用上は IDF が用いられることが多い)です.BM25F はこの $f_{t,d}'$ をフィールドごとに計算し,その重み付き和を文書全体に対する単語頻度として BM25 のスコアを計算します.式で書くと以下のようになります.
$$ f_{t,d}'=\sum_{s \in S} v_s \frac{f_{t,d,s}}{(1-b_s)+b_s\frac{l_{d,s}}{l_{\mathrm{s, avg}}}} $$ただし,この式に出現する記号は以下の通りです.
- $S$: 文書 $d$ が持つフィールドの集合
- $f_{t,d,s}$: 文書 $d$ のフィールド $s$ における単語 $t$ の出現頻度
- $l_{d,s}$: 文書 $d$ におけるフィールド $s$ の長さ(単語数)
- $l_{s,\mathrm{avg}}$: 文書集合におけるフィールド $s$ の長さの平均値
- $v_s, b_s$: フィールドごとに決めなければならないハイパーパラメータ
これにより,フィールドごとの単語頻度や文書長を考慮した検索が行えるようになりました.一方で BM25F は決めるべきパラメータ数が多くなってしまっています.BM25 では $2$ 個だったパラメータ数が BM25F では $2|S|+1$ 個になっています($|S|$ はフィールド数).そこで,よりシンプルな BM25F として BM25 の $f_{t,d}, l_d$ のかわりに以下の $f_{t,d}', l_d'$ を用いる手法も提案されています.
$$ f_{t,d}'=\sum_{s \in S} v_s f_{t,d,s}, \ \ \ l_d'=\sum_{s \in S} v_s l_{d,s} $$フィールドごとに決めるべきパラメータは $v_s$ のみとなっており,パラメータの個数は $|S|+2$ 個に減りました.
複数フィールド検索に関するその他の話題
まずパラメータチューニングについてです.BM25 や BM25F はハイパーパラメータを持っていますが,これらはどのように決めればよいでしょうか?これはなんらかアノテーションされたデータを用意し,NDCG などの評価指標を用いてパラメータを選択すればよいです.パラメータ探索アルゴリズムとしては,グリッドサーチの他に,座標降下法が用いられていることが多い印象です(あまり詳しくないので間違っている場合はこっそり教えて下さい…).
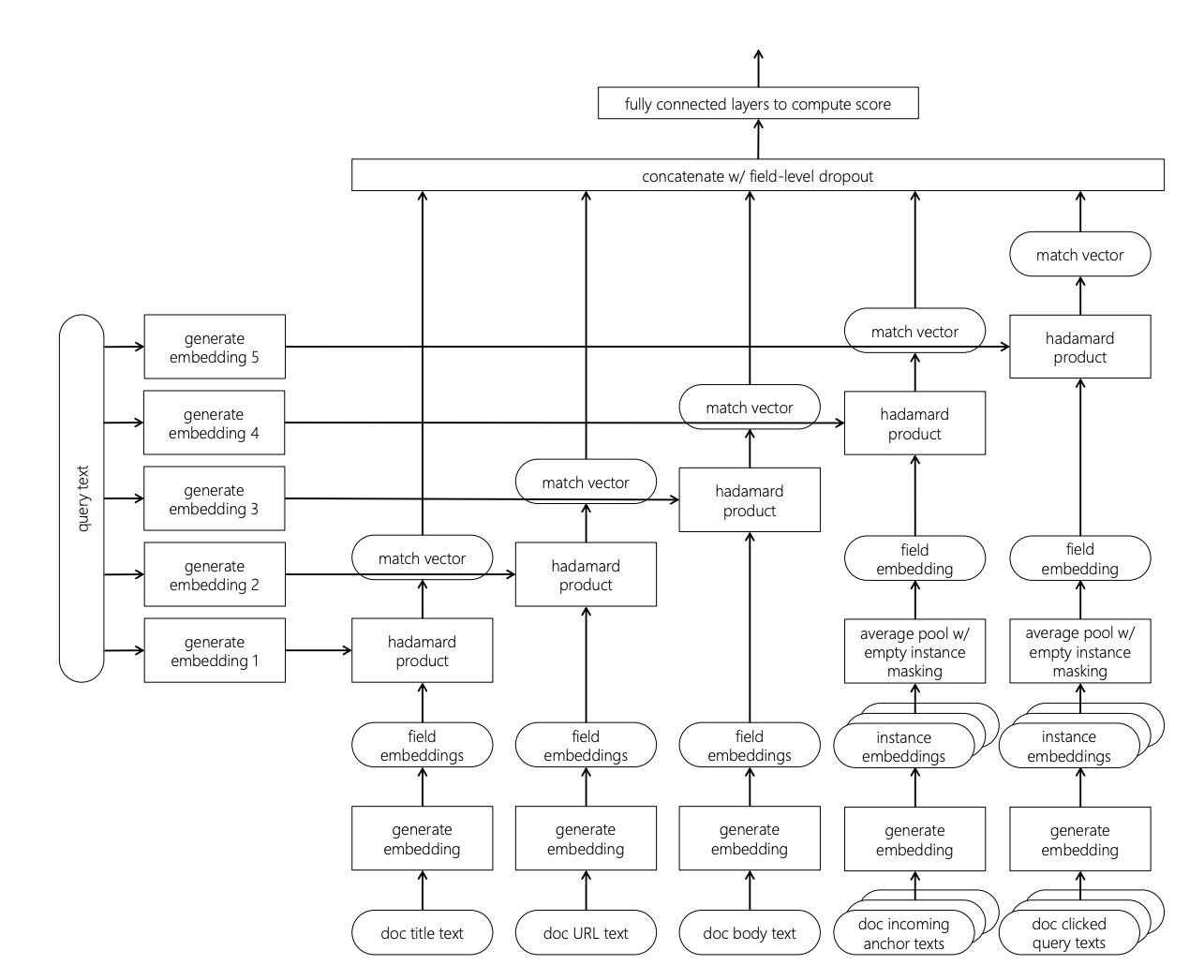
最後に手法的な発展の話です.近年はアノテーションされたデータが多く手に入るようになったことによって,機械学習的な手法(ランキング学習)が多く研究されている印象です.近年では深層学習を用いた検索アルゴリズムも研究されており,NRM-F5 もその 1 つです.NRM-F のアーキテクチャは以下の図の通りです(図は Mitra & Craswell11 の図 7.1 より).まず,フィールドごとに embedding をしてクエリの embedding とアダマール積をとった後,それらを結合し最終的なスコアを多層パーセプトロンで計算しています.NRM-F ではフィールドごとに embedding さえ計算できればよいため,画像やカテゴリなどテキスト以外でも適用可能です.さらに別の手法として,Attention 機構を用いた手法も提案されていたりします12.
おわりに
いつもなにげなく使っている BM25 も確率的ランキング原理というシンプルな仮定から始まり,様々な模索の上で出てきた式であることがわかり,読んでいて楽しい章でした.一方で BM25F あたりの話を書きながら,本当にこのあたりの話は使われているのだろうかという疑問がわきました.具体的には,複数フィールドをごちゃまぜにしてランキングすることに本当に意味はあるだろうか,という疑問です.個人的にはごちゃまぜにせずにフィールドごとに絞り込んで検索したいのではないかと思う一方で,この考え方は慣れている人向けであり,初心者向けにはキーワードが良いのかなあなどと考えていました.また,最近の Web サービスとかはログからえいやっとランキング学習してしている印象があり,BM25F をいまさら解説する意味もあるのかなあなどと考えていました.もしこのあたりの話(複数フィールド検索の話)に関して,最近のサービスではこうしているよ,みたいな知見がある人がいらっしゃる場合は教えていただけると嬉しいです.
また,Advent Calendar を企画してくださった @sz_dr さんありがとうございました.こういう機会でもなければブログから遠ざかってしまいがちなので,参加できてよかったと思っています(まあ締切と重なってしまい,最初の日程から別の日にしてしまってすみませんでした…).もし来年も情報検索・推薦系の Advent Calendar があれば参加したいです.
Yoshihiko Suhara: Notes on Probabilistic Information Retrieval -Probability Ranking Principle から BM25 まで-. 2012. http://sleepyheads.jp/docs/prob_ir.pdf ↩︎
ytanaka: 確率的情報検索について. 2019. https://ytanaka.hatenablog.jp/entry/2019/06/24/004452 ↩︎
AIcia Solid Project:【自然言語処理】tf-idf 単語の情報量を加味した類似度分析【Elasticsearch への道①】. 2020. ↩︎
AIcia Solid Project:【自然言語処理】BM25 - tf-idfの進化系の実践類似度分析【Elasticsearch への道②】. 2020. ↩︎
Zamani et al.: Neural Ranking Models with Multiple Document Fields. WSDM 2018. ↩︎ ↩︎
Choi et al.: Semantic Product Search for Matching Structured Product Catalogs in E-Commerce. Arxiv 2020. ↩︎
@rejasupotaro: 文書のランキングは情報推薦なのか? 2020. https://qiita.com/rejasupotaro/items/369804fe118270de27ec ↩︎
Zhang & Balog: Ad Hoc Table Retrieval using Semantic Similarity. WWW 2018. ↩︎
Robertson et al.: Simple BM25 Extension to Multiple Weighted Fields. CIKM 2004. ↩︎
Robertson & Zaragoza: The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval. 2009. http://www.mathcs.emory.edu/~eugene/cs572/lectures/foundations_bm25_review.pdf ↩︎
Mitra & Craswell: An Introduction to Neural Information Retrieval. https://www.microsoft.com/en-us/research/publication/introduction-neural-information-retrieval/ ↩︎
Balaneshinkordan et al.: Attentive Neural Architecture for Ad-hoc Structured Document Retrieval. CIKM 2018. ↩︎